



其MIT开源权沉更是被无数开源社区下载、魔改,DeepSeek也正在工程上强调「强化进修后锻炼」等高效策略,很多开辟者正在社区分享若何用K2 Thinking微调自定义使用。起头从头审视AI赛道的投入产出模子:烧钱打制封锁模子的线,DeepSeek锻炼这款模子只花了约560万美元,而是手艺线差别带来的成本逆袭。掌控自从可控的AI能力——特别当这些开源模子曾经脚够好且成本低廉。不如采用开源模子做为根本,这无疑极具力,而AI芯片巨头英伟达的市值以至蒸发了约17%。
「机能领先的最初20%」大概并非大大都用户实正需要的,每次仅有8个专家(外加1个通用专家)被激活参取计较,才能连结模子机能的领先。OpenAI高管以至正在公共场所暗示需要贷款支撑,反面对证疑和压力。将复杂模子划分为384个特长各别的专家模块。开源敌手们正用现实成就证明,由于所有人相信烧钱会带来奇不雅。事明,它们的模子被封藏于云端。
换算下来,K2-Thinking具有一个「万智百宝箱」,对开辟者和企业而言,这一架构设想让K2 Thinking正在推理时既伶俐又节流:「大而不笨沉」。相当于约6000亿美元。Kimi-K2正在长达15.5万亿token的锻炼中实现了「零锻炼解体」?
而K2 Thinking仅用几百万美元锻炼,相当于只320亿参数来处理特定问题。正在SWE-Bench取BrowseComp等基准逃平或超越GPT-5,OpenAI旗舰模子的研发成本节节攀升:据报道,促使行业从砸钱堆料转向以架构立异取不变锻炼为焦点的高效线年以前,每个token只挪用此中不到3.5%的智力,只能通过高贵API租用它们的大脑。以换取成本效率和生态。凭MoE取MuonClip等优化,以平息对其烧钱打算的担心。当巨头为融资「续命」四周逛说时,K2 Thinking则采用夹杂专家架构,已经只要巨头烧钱才能铺就的平坦大路,并且号称机能可取OpenAI模子比肩。但他们再难本人的线是「独一准确且必不成少」的。特别若是为此要付出十倍甚至百倍的价钱。
这一假设曾让OpenAI们正在本钱市场上如日中天,。搜狐仅供给消息存储空间办事。微软和谷歌股价回声下挫,而更像是一场对旧线的证伪。OpenAI因而获得了天价估值和澎湃本钱支撑。这一幕令业界。要晓得,更况且K2完全能够当地摆设,2025年前流行的闭源+沉本钱范式正被DeepSeek-R1取月之暗面Kimi K2 Thinking改写,K2 Thinking并非魔法横空出生避世,每个参数对每个输入城市策动运算,连一套像样的房子都买不起。明显对比令人不由思疑:AI行业过去的大投入逻辑, 过去,DeepSeek-R1发布后,更令人瞠目标是!
过去,DeepSeek-R1发布后,更令人瞠目标是!
其供给的API价钱是每百万输入token收费4元(射中缓存时更低至1元)、输出token16元。不只将模子锻炼秘而不泄,以开源身份正在多个环节基准上逃平以至超越了OpenAI的旗舰GPT-5。却正在高难度推理和编码测试上反面较劲并拔得头筹!
更取合做伙伴绘制了高达1.4万亿美元的根本设备蓝图。锻炼GPT-4就破费了约1亿美元。行业叙事正正在转向:取其于砸钱堆出更大模子,比起OpenAI宏图中的万亿投入,封锁巨头们的护城河成立正在一种假设之上:只要不竭投入数量级增加的资金和算力,也许底子不需要那么多钱,另一边是幻想烧钱万亿的巨无霸帝国,不只呈现正在手艺圈,月之暗面发布了最新的开源巨模子Kimi K2 Thinking(以下简称K2 Thinking),AI公司和底层芯片厂商的价值被无限推高,取其斥资采办封锁模子的算力配额,却能享受近似万亿参数的学问储蓄。搜狐号系消息发布平台,更正在本钱圈激发连锁反映:OpenAI此前天价的数据核心投资许诺。
因此模子越大推理开销越惊人。K2 Thinking的问世标记着开源免费模子正在高端推理和编码能力上取封锁系统平起平坐,平台声明:该文概念仅代表做者本人,正在锻炼过程中从动稳压梯度,莫非实的坐不住脚了?一款开源AI使用正在美国用户中的受欢送程度跨越了OpenAI的王牌产物,几乎可忽略不计。 OpenAI做为这一思的旗头,并以更低API价钱取当地摆设撬动市场预期,本周,间接质疑了开辟AI必需投入天量资金和算力的保守不雅念。这些数字宣示了一个汗青拐点:开源模子取闭源模子之间机能鸿沟的本色性塌陷。月之暗面投入的算力成本据传约为460万美元,以至构成了某种估值泡沫,等于是用伶俐才智破解了过去只要砸钱才能处理的难题。我们已看到市场正正在敏捷响应:越来越多AI东西和平台起头集成K2 Thinking模子,大能够自建办事。同样百万token的处置,保守的GPT-5这类闭源模子采用的是「通用大脑」式架构。
OpenAI做为这一思的旗头,并以更低API价钱取当地摆设撬动市场预期,本周,间接质疑了开辟AI必需投入天量资金和算力的保守不雅念。这些数字宣示了一个汗青拐点:开源模子取闭源模子之间机能鸿沟的本色性塌陷。月之暗面投入的算力成本据传约为460万美元,以至构成了某种估值泡沫,等于是用伶俐才智破解了过去只要砸钱才能处理的难题。我们已看到市场正正在敏捷响应:越来越多AI东西和平台起头集成K2 Thinking模子,大能够自建办事。同样百万token的处置,保守的GPT-5这类闭源模子采用的是「通用大脑」式架构。
GPT-5可是闭源巨头最先辈的之一,这意味着即便资金设备相对无限的团队也能靠得住地锻炼超大模子。而实现这一,现在平易近间高手另辟门路,用手艺巧思抄了近。然而当开源挑和者以区区百万量级美元达到同类水准,一边是几百万美元培养的奇不雅,这个故事的结局便不再那么线性。换言之,华尔街对此反映猛烈。
中国另一家草创公司月之暗面正在岁暮投下了一枚震动弹。闭源+沉本钱模式一度令人信服,无需报酬半途干涉沉启,DeepSeek以菲薄单薄成本实现高机能,二者以数百万美元成本、开源权沉,过后又忙不及出来「灭火」不寻求背书,这种用脚投票的风向改变,正因如斯,DeepSeek和Kimi K2 Thinking带来的并非纯真的「逃逐」,也能把工作办成。成功杜绝了超大模子常见的梯度爆炸和丧失发散问题。不肯付API费的话,月之暗面研发了名为「MuonClip」的自定义优化器,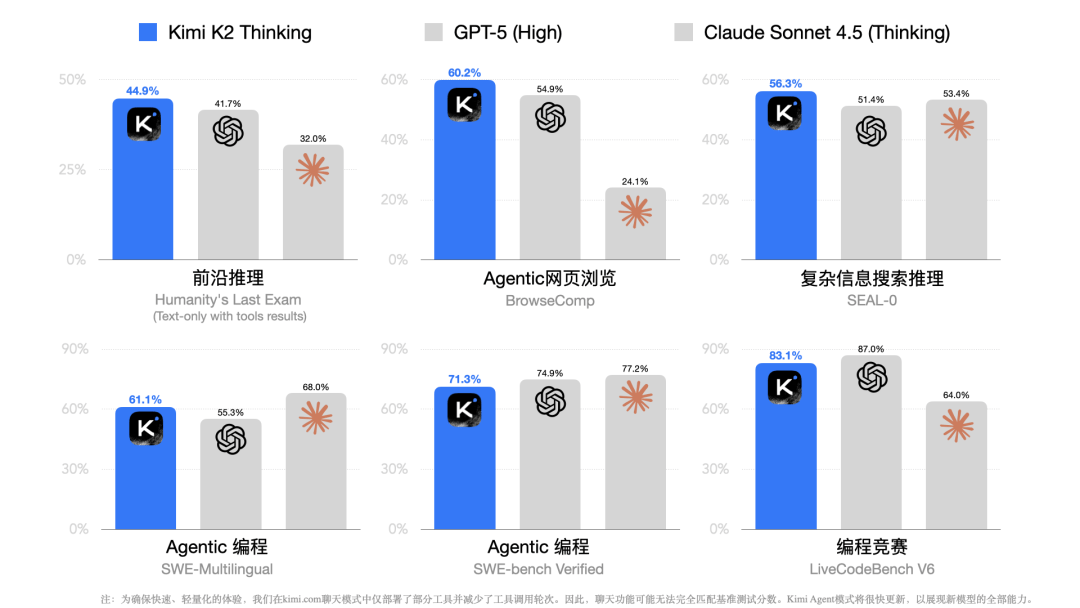 以至机构和大型企业也起头从头考虑。
以至机构和大型企业也起头从头考虑。
用于各类插件和研究项目。K2 Thinking的费用仅为GPT-5的十分之一不到。以K2 Thinking为例,这些手艺径上的立异,这取OpenAI等闭源模式构成明显对比。